About SAGE
An ensemble-learning model for predicting the commercial success of digital games on Steam — using only pre-launch attributes.
Project overview
This system is a thesis project developed at FEU Institute of Technology under the BS Computer Science with Specialization in Data Science program.
The research applies ensemble learning techniques (Random Forest, Gradient Boosting, XGBoost) combined through stacking to predict the commercial success of digital games on Steam using pre-launch features only.
Research team
- Balajadia, Gabriel Patrick A.
- Casas, Juan Carlo C.
- Estrada, Raphael G.
- Garcia, Aaron Jacob G.
Thesis adviser: Elisa V. Malasaga
Department: Computer Science, FEU Institute of Technology
Submission: March 2026
Methodology
Data source
Trained on 10,000 games collected from the Steam Web API and SteamSpy, focusing exclusively on pre-launch attributes (no post-launch reviews or playtime).
Target variable
Games are classified into 6 ordinal owner tiers:
- Class 0: ≤10K owners — Common Indie
- Class 1: 10K–35K owners — Niche
- Class 2: 35K–75K owners — Growing
- Class 3: 75K–150K owners — Established
- Class 4: 150K–350K owners — Popular
- Class 5: ≥750K owners — Breakout Hit
Note: classes 5–8 from the original 9-class scheme were merged into Class 5 due to sparse samples.
Ensemble architecture
- Base models: Random Forest, Gradient Boosting, XGBoost (trained independently)
- Meta-learner: XGBoost classifier combining base-model probabilities
- Random Forest — robust feature importance, handles non-linearity
- Gradient Boosting — sequential error correction, reduces bias
- XGBoost — regularization, handles missing data, captures complex patterns
Feature engineering
From raw Steam data, 48 pre-launch features were extracted and engineered:
- Raw (41): pricing, release month, genre, platform, languages, screenshots, trailers, developer/publisher info, Steam features, tags, DLC
- Composite (7): store page quality, marketing investment, platform reach, publisher backing, localization, Steam integration, mature-content flag
Headline results
Model interpretability (SHAP)
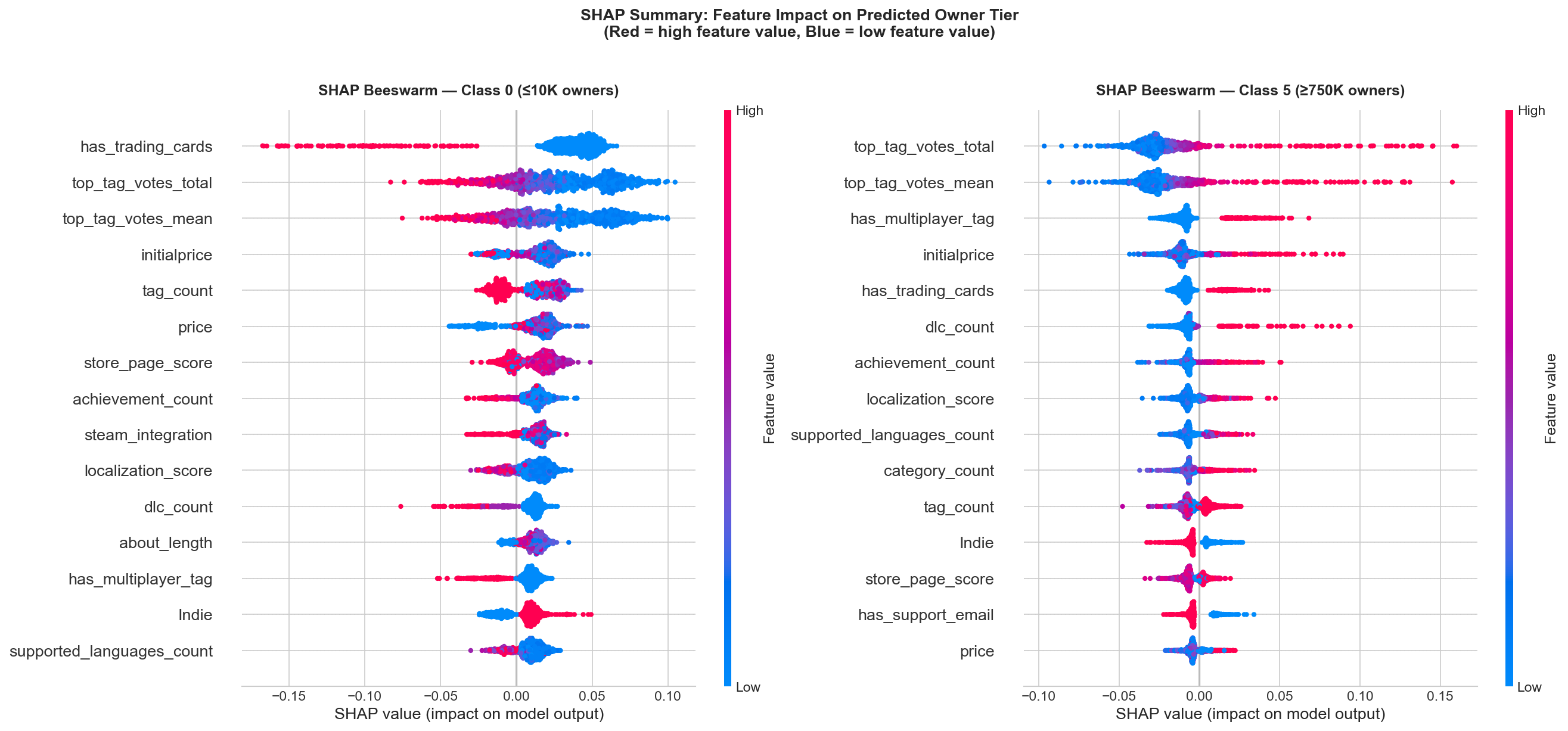
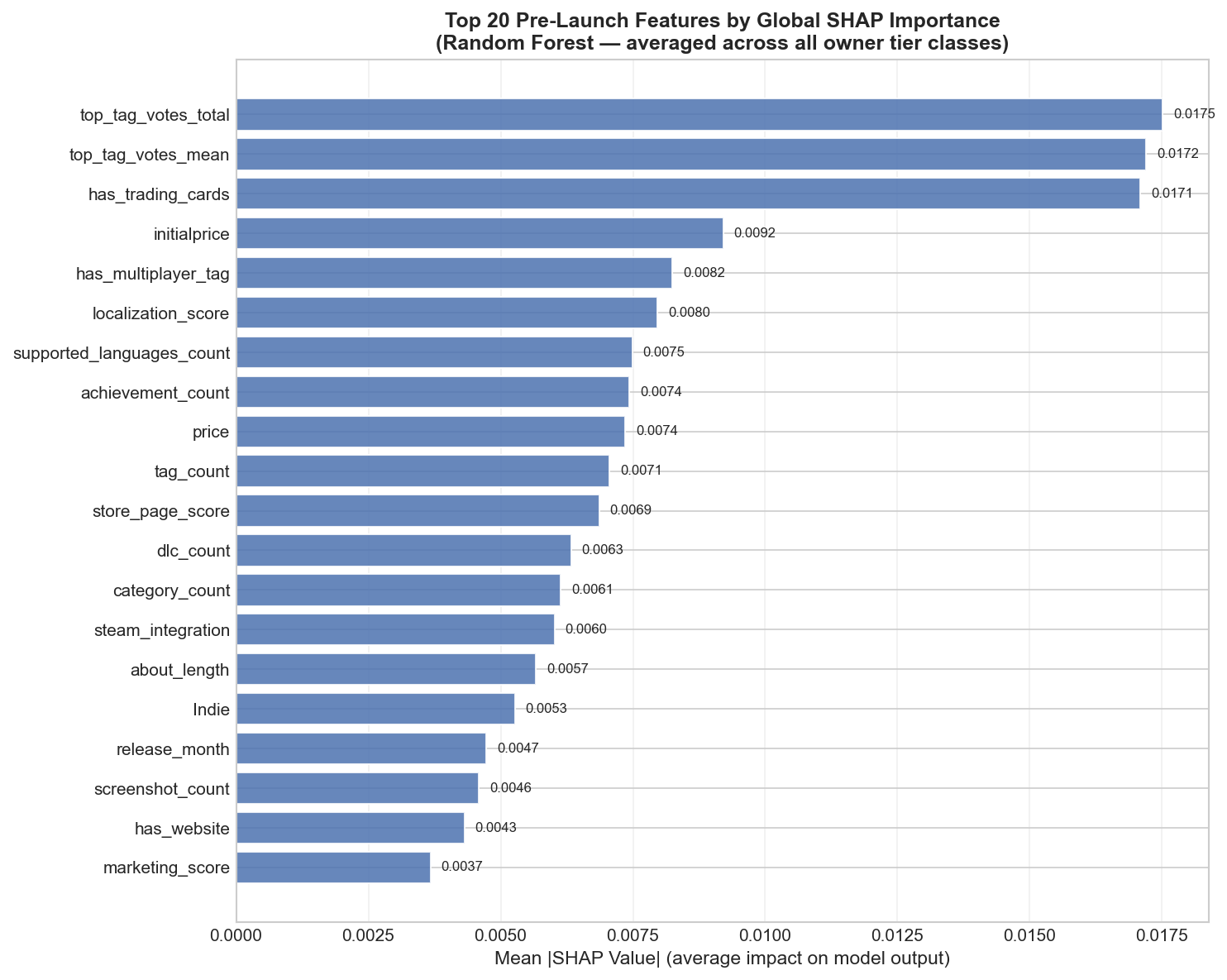
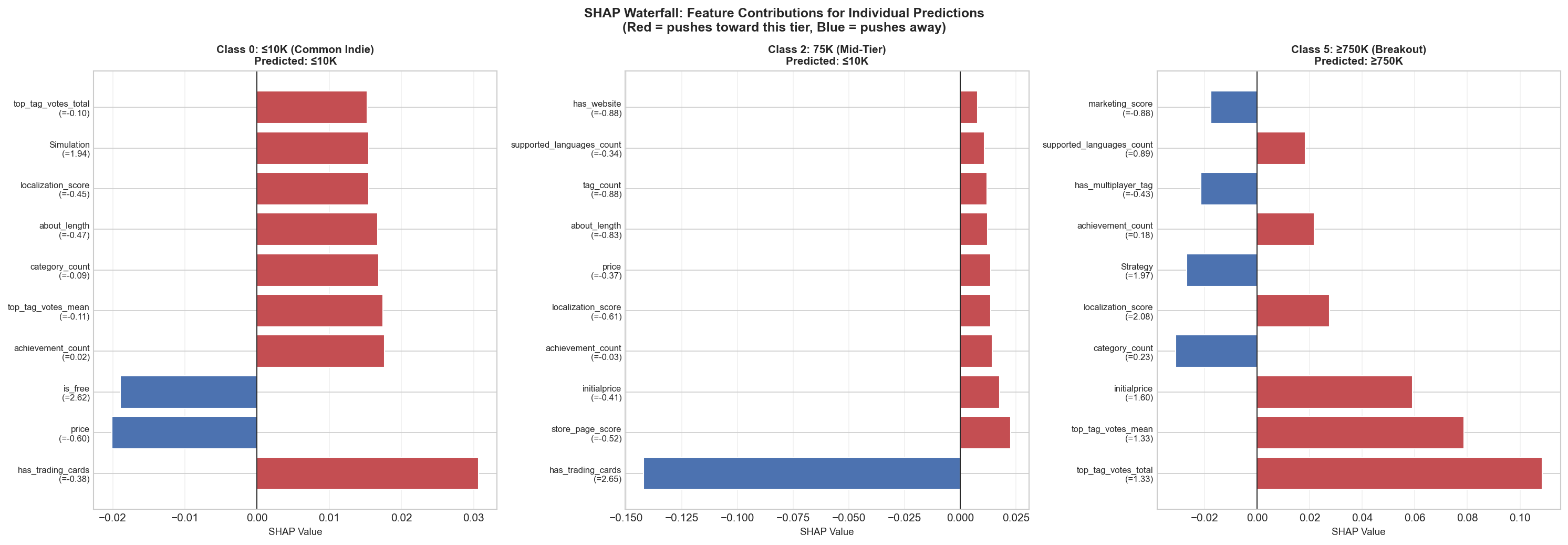
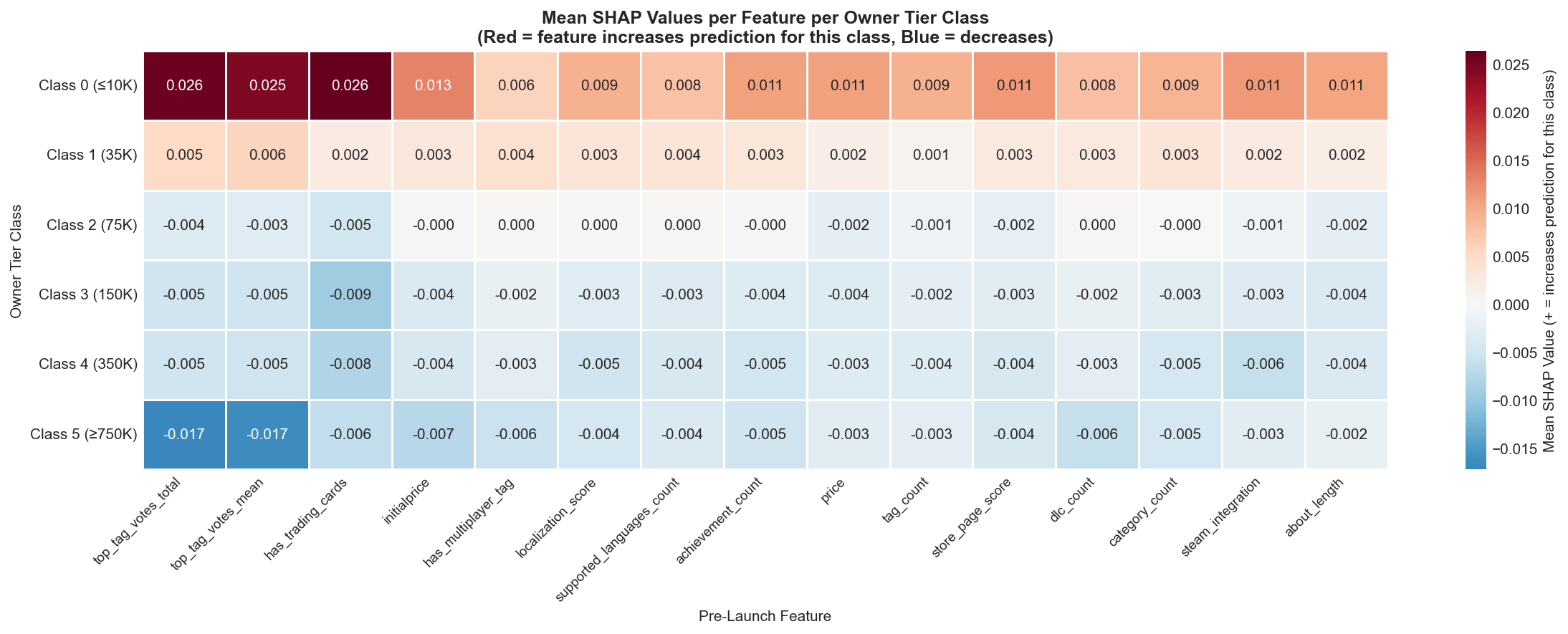
SHAP (SHapley Additive exPlanations) values were computed to understand which features most strongly influence predictions and how they impact each class.
Global feature importance
Mean absolute SHAP
Top single-prediction explanation
Class-specific SHAP values
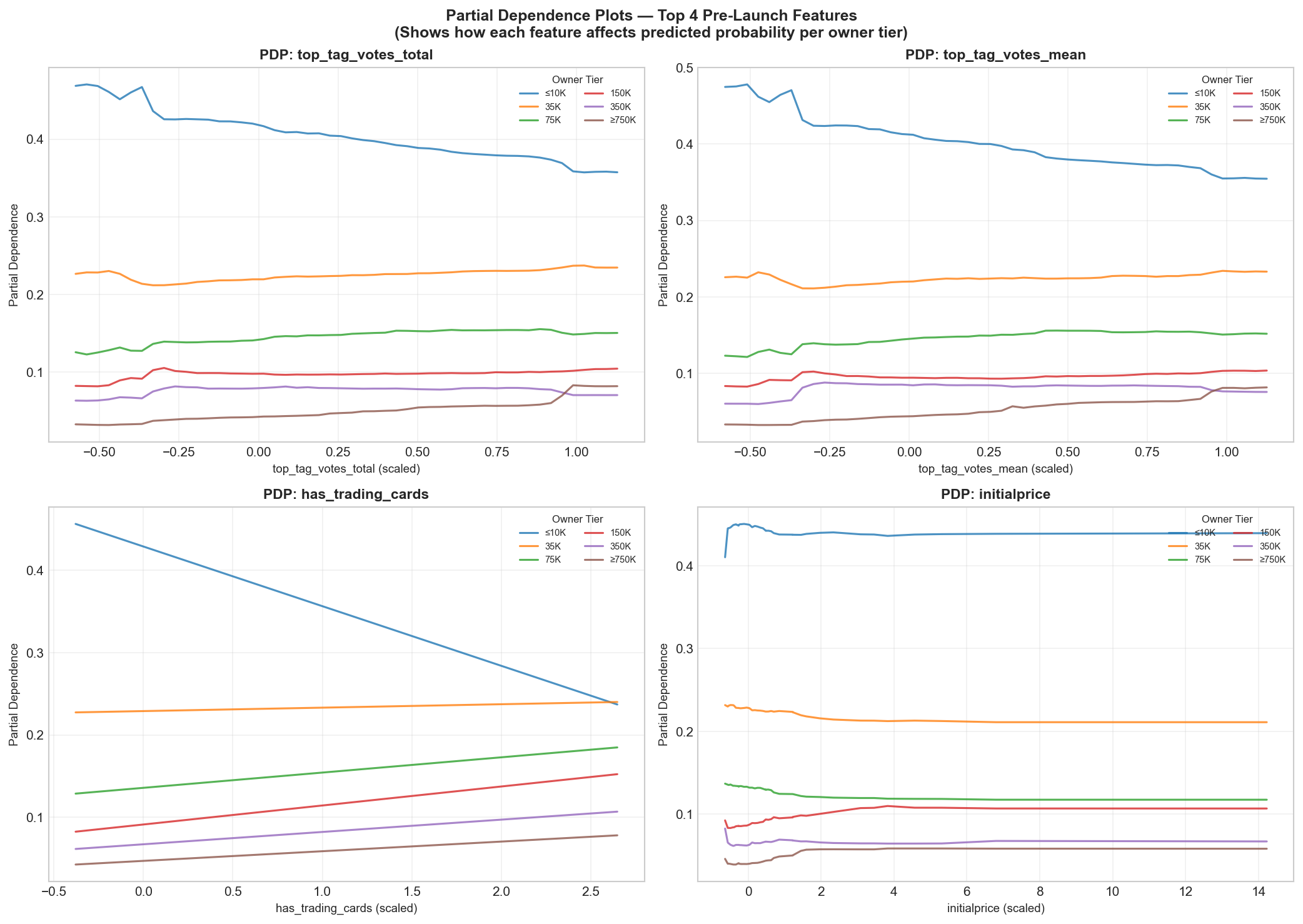
Partial dependence (top 4)
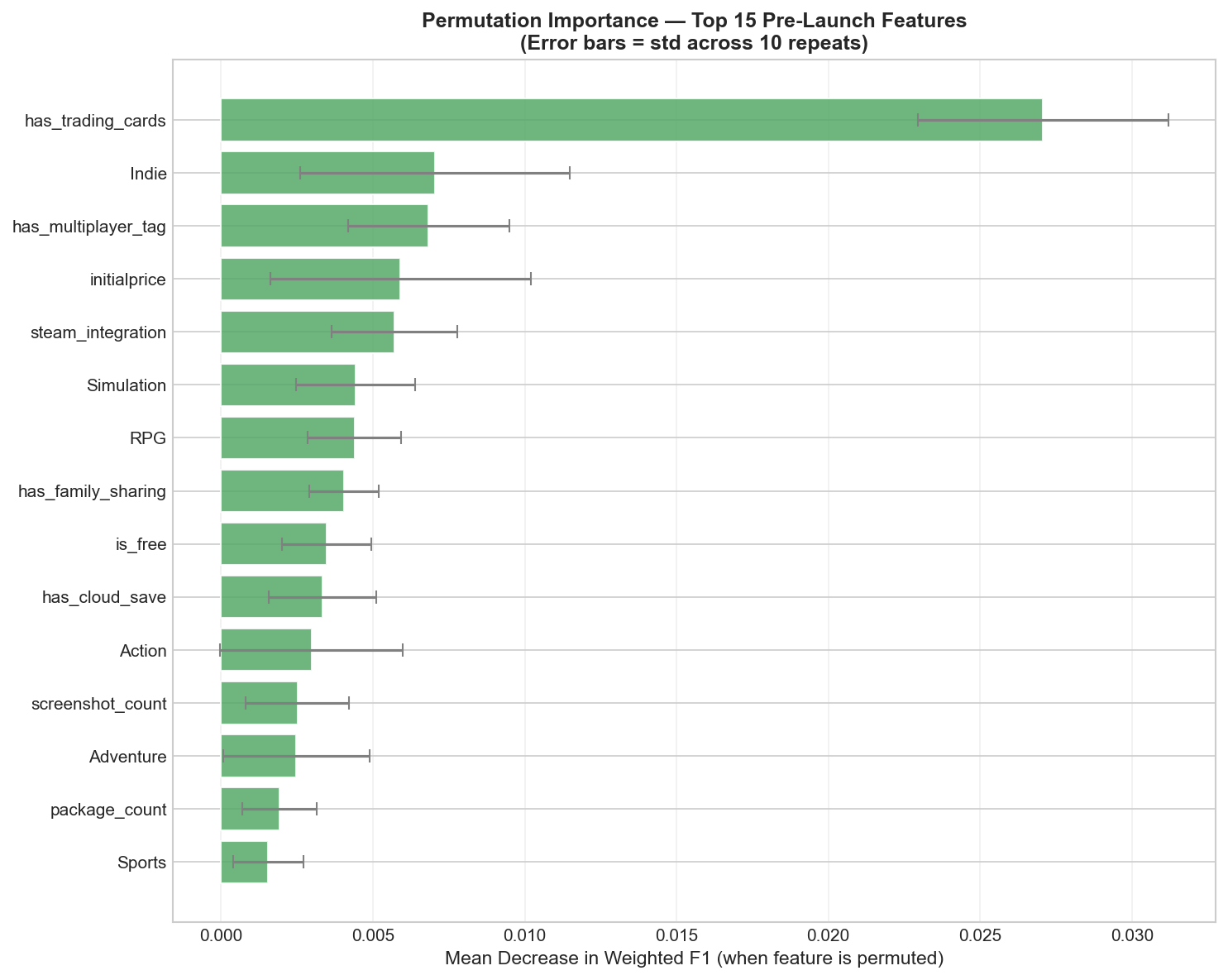
Permutation importance
Note: Click any plot to enlarge. Source files live in model_outputs_prelaunch/shap_outputs/; copy them into static/images/ for display.
Key findings
- Most influential features: store page quality (trailers, screenshots, detailed descriptions), publisher backing, platform reach, localization.
- Genre effects: indie dominates the dataset but shows lower average success; Action, Strategy, RPG correlate with higher tiers.
- Pricing strategy: mid-range ($9.99–$19.99) performs best. Free-to-play is bimodal (very successful or fails fast).
- Release timing: October–December slightly outperforms (holiday sales effect).
- Steam integration: achievements, trading cards, and Workshop support correlate positively with owner tier.
Limitations
- Platform-specific: Steam only; predictions for Epic / GOG / consoles are unreliable.
- Temporal drift: gaming trends evolve; retrain periodically with fresh data.
- Data quality: SteamSpy provides estimated owner ranges (not exact counts), introducing noise.
- Causation vs correlation: high prediction ≠ guaranteed success — game quality matters most.
- Niche genres: under-represented genres (Racing, Sports) are less reliable.
Download full thesis
The complete thesis document is available for download:
Download thesis PDFIf the PDF is not available, place it at static/thesis/Bit-by-Bit_Thesis.pdf.
References
- Dietterich, T. G. (2000). Ensemble Methods in Machine Learning. Multiple Classifier Systems.
- Ma, X. (2025). Predicting Video Game Success Using Multi-Platform Data.
- Mienye, I. D., et al. (2022). A Survey of Ensemble Learning Techniques.
- Wood, M., et al. (2023). Diversity in Ensemble Learning: Theoretical and Empirical Analysis.
- Andraž, P., et al. (2021). Validating Steam as a Data Source for Success Prediction.
- Kainz, F., & Pirker, J. (2023). Large-Scale Steam Data Collection and Analysis.
Acknowledgments
Our thanks to thesis adviser Ms. Elisa V. Malasaga for her guidance, and to the FEU Institute of Technology Department of Computer Science for resources and support. Special thanks to the maintainers of scikit-learn, XGBoost, SHAP, Pandas, Flask, and Gunicorn.